February 25, 2026
The case for building your own AI benchmark

For the past two years we’ve been developing agentic AI systems. Every time we changed the prompt or system design with the aim to improve it, someone would hit us with “Is this actually better?”. The honest answer was usually “yeah… feels like it”. Well, that wasn’t good enough.
High-quality testing provides the essential confidence that engineered solutions behave reliably. However, applying this rigour to generative AI systems, particularly those built on complex, agentic designs, turns out to be surprisingly challenging.
In this post, we want to share a simple, lightweight evaluation framework that gave us real, quantifiable KPIs for goal-oriented conversational agents.
Our main goal is building intelligent solutions where flexibility and personalisation are essential, while still ensuring security, consistency and product-level goal delivery.
But how do we measure the quality of an AI Agent whose behaviour is intentionally flexible? How do we assess whether a particular prompt, system design, or constraint setup leads to better goal coverage and interactions that feel natural and positive, without falling back to rigid scripting?
Research rightly calls for a more holistic evaluation of agentic systems. This comes at different angles: looking not only at individual exchanges, but at the full conversation; numerically versus in natural language; evaluating not only objective qualities like coherence, but also more subjective ones like creativity or humour.
However, the traditional NLP metrics like BLEU or ROUGE fall short. They do not capture flow, goal progression, or whether the agent used the right tools at the right time. And they don't help detect hallucinations either.
Human evaluation is just not sustainable and does not scale.
LLM-as-a-judge can help but asking a model to numerically rate an entire conversation, including executed tool calls, and reliably judge both flow and goal execution is still unreliable, difficult to calibrate and audit, and lacks the granularity needed for actionable insights.
In our own systems, we noticed something simpler: despite the flexibility of agentic conversations, we almost always expected them to follow a recognisable structure. There is a main objective and a set of enabling sub-goals or milestones the agent must hit to fulfil it.
Here’s a concrete example for a lead-generation assistant:
Main objective: Create a lead and initiate a follow-up with the user
Rough desired conversation structure:
Ideally, we need a way to quantitatively verify whether conversations actually follow this intended structure.
This led us to thinking: what if we extend the concept of Dialogue Act Recognition (DAR), a technique from computational linguistics, and adapt it to evaluate modern goal-oriented AI Agents in conversations?
The core principle is simple: if each message of the conversation can be assigned a structural label, representing its functional role, we get a representation that is consistent, trackable, and measurable. This provides a foundation for tracking critical milestones and structural integrity of conversations.
The advantage? Structure and classification are inherently measurable, giving us quantifiable KPIs to work with.
Dialogue Acts are traditionally defined as atomic units of conversation with a specific linguistic function.
In our case of agentic systems, we care less about linguistic form and more about the functional role a turn plays in progressing the conversation.
So, instead of classifying fine-grained linguistic acts (e.g. “Quotation”, “Or clause”, “Self-talk”, “Apology”), we segment the conversation into high-level, goal-oriented structural steps. These are specific milestones that reflect the product’s requirements: some mandatory, others optional but desirable.
For our lead-generation assistant, an example label set could look like:
[“greeting/closing”, “question answering”, “contact proposal”, “contact detail gathering“, ”extracted data playback”, “follow-up confirmation”, “none”]
Now, each message (both from an agent and a user) is classified as one of these categories, conditioned on the context of the previous message.
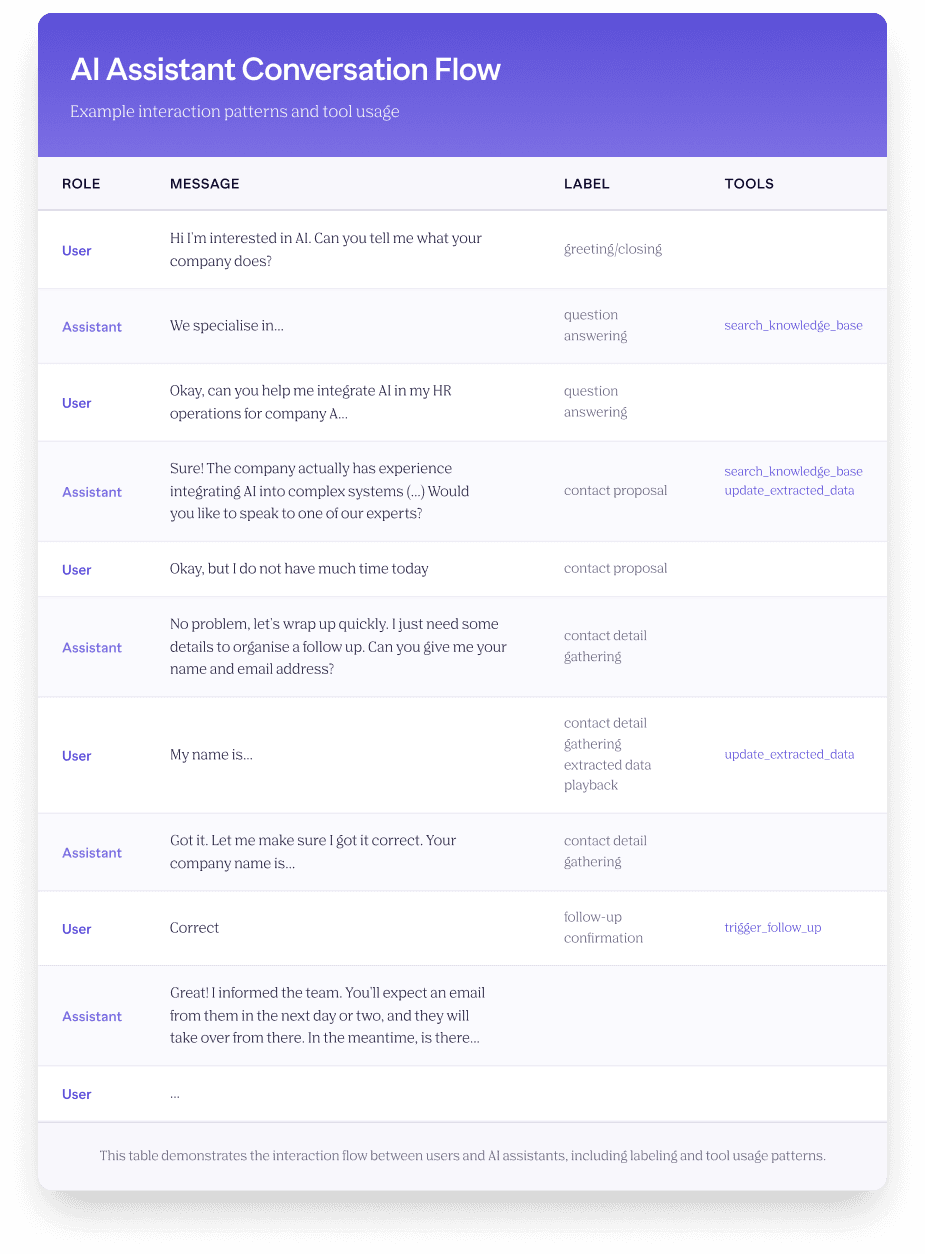
This structural representation forms the basis for quantifying the flow and evaluating whether the agent progressed the conversation in a coherent, goal-aligned way.
In our experiments, we found that traditional classifiers like Bart struggled with context and semantic nuance. LLMs, however, tend to naturally handle the conversational history and context better, and adapt better to ambiguous or indirect language. Particularly, LLMs flourished when context-tuned with some critical few-shot examples relevant to the specific use case.
For example, we explicitly tuned the model to ensure messages like “thanks, talk later!” were correctly categorised as a general “greeting/closing”, rather than a “follow-up confirmation”, reserving that critical label only for messages containing explicit consultation or meeting details.
Once every message in a conversation has a label, the entire interaction becomes a sequence of functional states. This makes it possible to define quantitative KPIs that reflect how well the agent followed the intended flow.
More importantly, each structural area corresponds to a specific kind of behaviour we want the agent to exhibit, often tied to internal tooling or constraints.
For instance, the “question answering” area requires validating that the agent grounded its answers in actual knowledge (e.g. via calling specific search tools), or ensuring the “contact confirmation” area only appears after a “contact” proposal and alongside a specific tool call for scheduling. This provides a clear method to identify critical hallucination points and broken workflows where the agent is “saying” one thing but not executing the required action.
With all that in mind, we can now move beyond subjective feeling and define a set of quantitative KPIs to monitor. For the lead-gen bot, we wanted to ensure against premature closing, avoid conversations that feel overly “salesy”, and verify that the collected data is correct (a critical factor for agents integrated with voice solutions).
Here’s a non-exhaustive list of KPIs that worked for us:

Such a “structural audit” can flag gaps early on. It helps diagnose broken flows, is easily customisable and surfaces some systemic issues (hallucinations, say-do discrepancies of the chatbot) or specific conversation phases that need attention.
We integrated it into our evaluation suite, pairing it with powerful user simulations and thoughtfully designed test conversations for input generation. It has proven valuable, especially in the early-stage development.
This method works best for goal-oriented, task-driven conversations with identifiable milestones. It's less suited to open-ended dialogues or conversations with highly variable structures. The quality of insights depends directly on the classification accuracy -garbage in, garbage out applies here.
That said, even in challenging scenarios with non-cooperative or adversarial users, tracking what we can control, the behaviour of the agent itself, remains valuable. And in practice, these difficult conversations often reveal more about the product’s weaknesses than the happy-path examples ever do.
What’s next? We are exploring extensions and complementary signals: user sentiment monitoring, keyword-level behavioural proxies (e.g. agent’s apologies), and more.
If you’re building goal-oriented conversational AI, we encourage you to experiment with structural evaluation. Start with 4-6 area labels, collect classification data (or simulate), and see which KPIs correlate with the outcomes you care about.